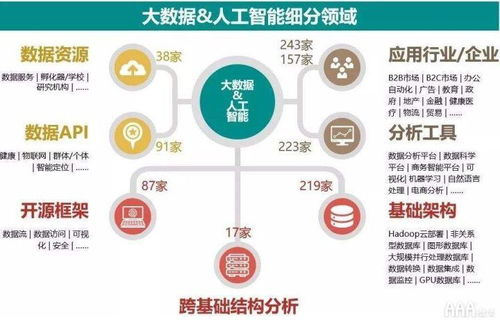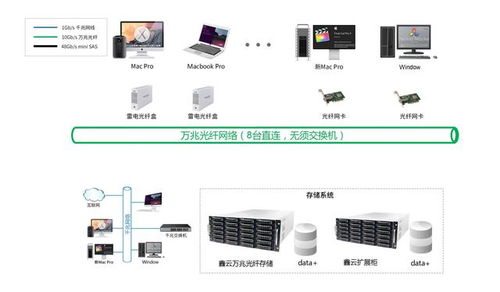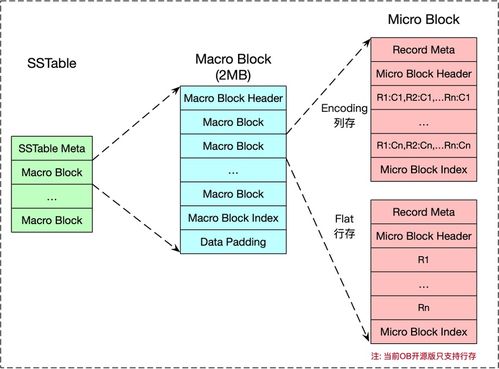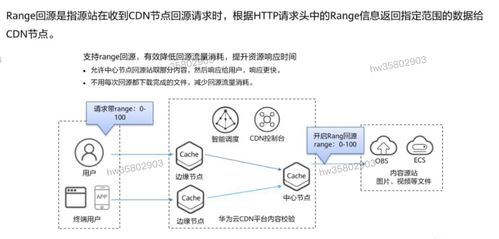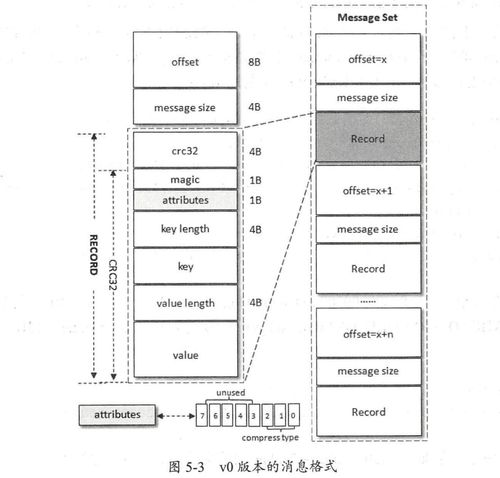
Hadoop 是当今大数据领域的核心技术之一,以其高效的数据处理与存储能力广泛应用于各行各业。作为大数据生态系统的重要支柱,Hadoop 提供了一套可靠的分布式数据存储和处理框架,能够处理海量结构化与非结构化数据。本部分将重点介绍 Hadoop 的架构组成,以及大数据存储与数据处理服务的基本原理和实现方式。
一、Hadoop 架构概述
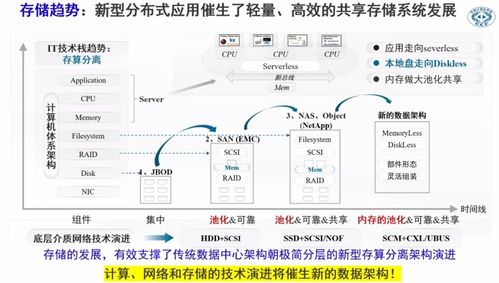
Hadoop 架构主要由两大核心组件构成:HDFS(Hadoop 分布式文件系统)和 MapReduce。HDFS 负责数据的分布式存储,它将大规模数据分割成块(blocks),并分散存储于集群中的多个节点,确保数据的高可用性和容错性。而 MapReduce 则是一种分布式计算模型,包含两个阶段:Map 阶段负责数据的并行处理与转换,Reduce 阶段则对中间结果进行汇总,生成最终输出。Hadoop 还包括 YARN(Yet Another Resource Negotiator)作为资源管理器,用于分配计算资源和管理任务调度,进一步优化了集群性能。
二、大数据存储服务
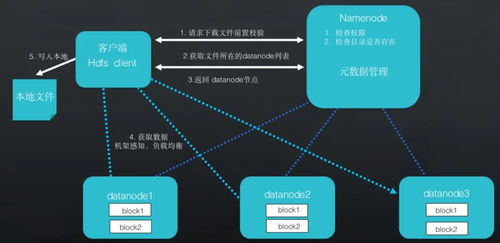
Hadoop 的核心存储服务依赖于 HDFS。HDFS 设计初衷是支持海量数据存储,适合一次写入、多次读取的场景。它采用主从架构,包括 NameNode(主节点)和多个 DataNode(从节点)。NameNode 负责管理文件系统的元数据(如文件和目录结构),而 DataNode 则存储实际数据块。这种分布式存储方式不仅提升了数据的可靠性和冗余备份能力,还能通过横向扩展轻松应对数据增长。除了 HDFS,Hadoop 生态中还有其他存储选项,例如 HBase(分布式 NoSQL 数据库),适用于实时读写场景,以及云存储服务整合,为大数据应用提供灵活性和扩展性。
三、数据处理与存储服务集成
在 Hadoop 框架下,数据处理与存储服务紧密结合,共同支持大数据应用。MapReduce 作为经典的数据处理引擎,可以高效处理存储在 HDFS 上的数据,实现批量计算任务。随着技术演进,Hadoop 生态系统还引入了更高级的处理工具,如 Apache Spark,它通过内存计算加速数据处理过程,并支持流处理和机器学习。数据仓库解决方案如 Hive 和 Pig 提供了类 SQL 接口,简化了数据查询与分析。这些服务通过集成的资源管理(如 YARN)和存储抽象,使企业能够构建可扩展的大数据平台,有效应对数据存储、处理和分析的多样化需求。
Hadoop 架构通过其分布式文件系统和并行计算能力,奠定了大数据存储与处理的基础。理解 HDFS 的存储机制和 MapReduce 的数据处理流程,是掌握大数据技术的关键。随着云计算和实时分析需求的增长,Hadoop 生态持续演进,提供更加高效、灵活的数据服务,助力企业从海量数据中提取价值。