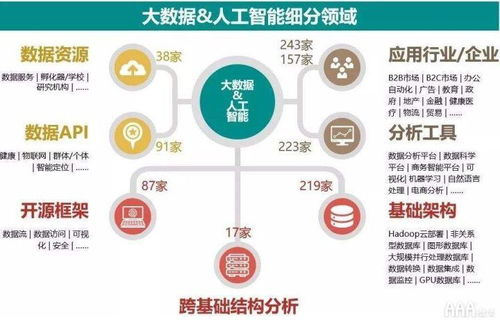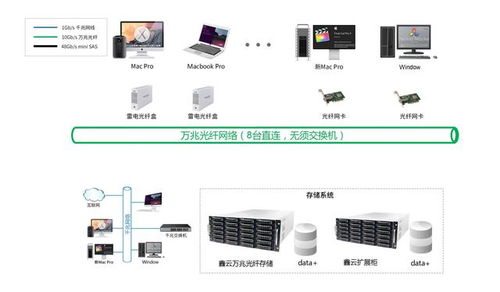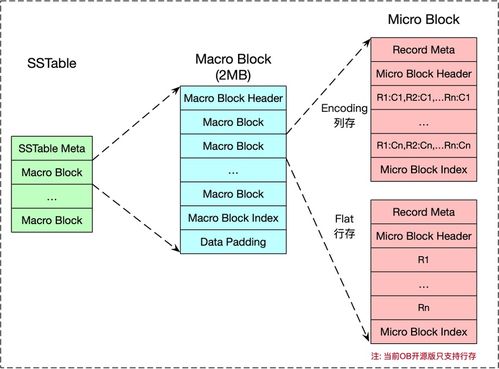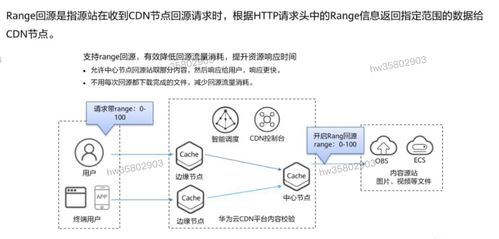
在当今数据驱动的时代,数据处理与存储服务不仅是后端开发的核心技能,更是面试中考察候选人综合能力的重要维度。从文件读取到复杂数据结构的存储,再到数据库的设计与优化,这一系列操作构成了数据处理服务的关键链路。本文将围绕这一主题,模拟真实面试场景,层层递进地探讨几个经典问题,看看你能接住几招。
第一招:基础文件读取与解析
面试官常以实际案例开场:“给定一个包含层级关系的文本文件(如部门-员工树),如何高效读取并解析为内存中的树结构?”
这一问考察基本功。关键在于选择合适的文件格式(如JSON、XML、CSV或自定义分隔格式)和解析策略。例如,对于JSON格式,可使用标准库(如Python的json模块)直接加载为字典或列表,再递归构建树节点。对于大型文件,则需考虑流式读取(逐行或分块)以避免内存溢出,并利用迭代器或生成器优化性能。解析过程中,异常处理(如格式错误、编码问题)和边界条件检查(如循环依赖)是加分项。
第二招:树结构的内存存储与操作
当数据读入内存后,面试官会追问:“如何设计树的数据结构?支持哪些操作(如查找、插入、删除、遍历)?”
这考验数据结构设计能力。常见方案包括:
- 节点类(Node class)存储节点值、子节点列表及可选父节点引用。
- 使用字典或映射(如邻接表)表示节点关系,适用于稀疏树或需快速查找的场景。
操作实现上,需明确遍历方式(深度优先DFS、广度优先BFS)及应用场景。例如,DFS适合路径搜索,BFS适合层级统计。复杂操作如删除子树,需注意内存释放(在垃圾回收语言中)或引用管理。若面试涉及多线程环境,还需考虑并发安全(如加锁或使用不可变结构)。
第三招:持久化存储与数据库设计
核心难点来了:“如何将树结构持久化到数据库中?如何设计表结构?”
这是区分初级与高级开发者的关键。常见设计方案包括:
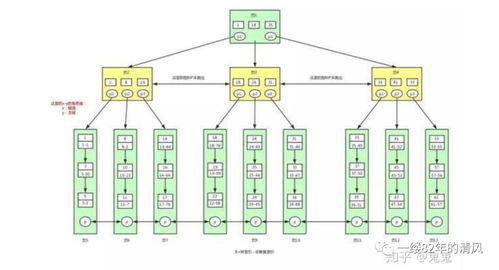
- 邻接表(Adjacency List):每行存储节点ID和父节点ID。简单易用,但查询子树需递归,效率较低,适合深度不大的树。
- 路径枚举(Path Enumeration):存储节点路径字符串(如“1/2/3”)。查询快速,但更新路径时需维护一致性,适用于读多写少的场景。
- 嵌套集(Nested Set):为节点分配左右值,表示遍历顺序。查询子树效率高,但插入删除复杂,适合静态或低频更新的树。
- 闭包表(Closure Table):额外存储节点间所有祖先-后代关系。空间换时间,查询和更新都较平衡,是通用性较强的方案。
面试中,需根据业务场景(如频繁更新、查询模式)权衡选择。例如,电商分类树可能用闭包表,而组织架构变更频繁时邻接表更灵活。
第四招:性能优化与扩展性
进阶问题常聚焦实战:“当树数据量极大(如百万节点)时,如何优化查询和存储?如何支持分布式环境?”
这需要系统级思维。优化策略包括:
- 数据库层面:添加索引(如父节点ID索引)、分区表(按层级或子树分区)、使用物化视图缓存常用查询结果。
- 缓存策略:引入Redis等缓存层,存储热点子树或路径信息,减少数据库压力。
- 异步处理:将耗时的树更新操作队列化,避免阻塞主线程。
对于分布式场景,可考虑分片存储(如按子树分片到不同数据库节点),但需解决跨分片查询和事务一致性问题。NoSQL数据库(如MongoDB的文档嵌套)也可能成为选项,但需评估其查询灵活性与数据一致性。
第五招:实际场景与故障处理
面试官可能抛出开放性问题:“如果树数据在文件中被意外损坏,如何设计恢复机制?如何监控存储服务的健康状态?”
这考察工程素养。恢复机制可包括:
- 备份与日志:定期备份树结构快照,结合操作日志(如WAL)实现增量恢复。
- 校验与修复:在文件中添加校验和(如MD5),读取时验证完整性;设计修复工具,基于冗余信息(如闭包表中的多重关系)重建损坏节点。
监控方面,需关注指标如查询延迟、存储空间增长、错误率等,并设置告警阈值。微服务架构下,可通过健康检查接口和分布式追踪定位问题。
从文件读取到树的存储,看似线性的流程,实则涵盖了数据解析、结构设计、持久化、优化及运维的全链条。面试中,除了技术实现,沟通思路(如先明确需求再选方案)和权衡取舍(如性能 vs. 复杂度)同样重要。掌握这些招数,不仅能应对面试,更能为构建稳健的数据处理服务打下坚实基础。下次面试,你能接住几招呢?