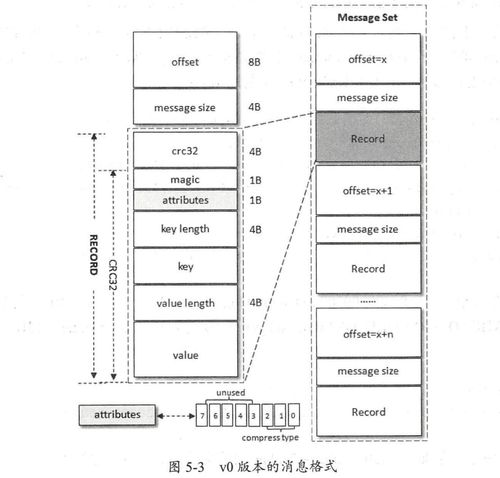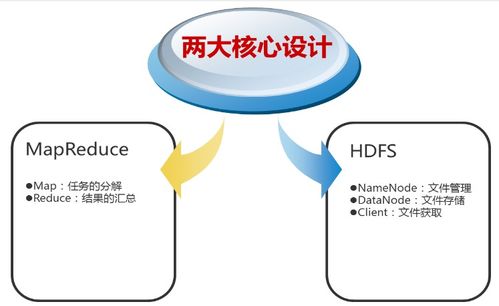
在大数据时代,Hadoop以其强大的分布式计算和存储能力,成为处理海量数据的核心框架。仅仅拥有处理能力还不足够,如何将处理后的数据以直观、可理解的方式呈现出来,即大数据可视化,同样至关重要。以国内知名技术社区CSDN为例,其数据处理与存储服务的实践,为Hadoop生态系统下的数据可视化应用提供了宝贵的参考。
一、Hadoop数据处理与存储服务的核心构成
Hadoop生态系统为大数据处理与存储提供了坚实基础。其核心包括:
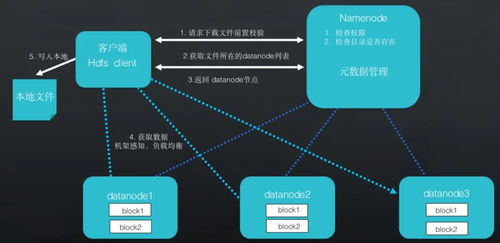
- 分布式文件系统HDFS:作为数据存储的基石,HDFS能够可靠地存储PB级别的数据,并通过数据块复制机制保证高容错性。它为后续的数据处理提供了统一、高吞吐量的数据访问接口。
- 分布式计算框架MapReduce/YARN:MapReduce编程模型允许开发者编写并行处理海量数据的程序。而YARN作为资源调度器,管理着集群的计算资源,使得Spark、Flink等多种计算框架可以高效运行其上,完成复杂的数据转换、清洗和聚合任务。
- 数据仓库工具Hive:Hive提供了类SQL的查询语言(HQL),将结构化数据文件映射为数据库表,大大降低了大数据查询和分析的门槛,是生成可视化所需汇总数据的关键工具。
这些组件共同构成了一个从原始数据存储到初步处理的数据管道,为可视化准备了“原材料”。
二、大数据可视化:从数据到洞察的关键桥梁
数据处理之后,可视化是将数据价值传递给最终用户的关键一步。在Hadoop生态中,可视化通常不是由Hadoop核心组件直接完成,而是通过以下方式实现:
- 数据提取与聚合:利用Hive、Spark SQL或Impala等工具,从HDFS或HBase中查询和聚合出可视化所需的维度、指标数据。这些数据通常被汇总为结构清晰的中间结果。
- 数据导出与对接:将聚合后的结果数据导出到关系型数据库(如MySQL)、分析型数据库或直接通过API接口,供前端可视化工具调用。
- 可视化工具应用:前端使用专业的可视化库(如ECharts、D3.js)或商业智能(BI)工具(如Superset、Tableau,这些工具也支持直接连接Hive等数据源),将数据转化为图表、仪表盘、地图等直观形式。
三、CSDN场景下的实践启示
以技术社区CSDN为例,其平台产生了海量的用户行为数据、文章数据、交互数据等。其数据处理与可视化流程可能涉及:
- 数据存储:用户日志、文章内容、评论点赞等原始数据存入HDFS,构成数据湖。
- 数据处理:通过MapReduce或Spark作业进行数据清洗(如去噪、归一化)、关键指标计算(如每日活跃用户数、热门文章排行、技术趋势分析)。处理后的结构化数据可存入Hive表或HBase。
- 服务与可视化:
- 对内运营:数据分析团队使用BI工具连接Hive,制作仪表盘,实时监控社区流量、内容产出、用户增长等核心运营指标,驱动决策。
- 对外产品:在CSDN博客、排行榜等产品页面,后端服务从处理后的数据存储中查询数据,前端通过可视化图表展示“热门技术标签”、“博主影响力指数”、“学习路径推荐”等,增强用户体验和社区互动。
- 架构整合:CSDN的实践很可能采用了分层架构,从原始数据层、数据仓库层到应用数据层,Hadoop服务于底层海量数据的批处理与存储,而上层应用和可视化则依赖于更实时、接口友好的数据服务。
四、挑战与未来方向
尽管Hadoop生态强大,但在支撑实时可视化方面也面临挑战:
- 实时性:传统的MapReduce批处理延迟较高。解决方案是引入Spark Streaming、Flink等流处理框架,构建Lambda或Kappa架构,实现近实时数据处理和仪表盘更新。
- 交互式查询性能:针对即席查询(Ad-hoc Query)需求,可以搭配使用Impala、Presto或Druid等引擎,对HDFS或Hive中的数据实现秒级查询响应,直接赋能交互式可视化分析。
- 数据治理与安全:在可视化过程中,需建立完善的数据权限管理体系,确保不同角色(如运营、管理员)看到其权限范围内的数据可视化视图。
结论
Hadoop大数据可视化是一个系统工程,它紧密连接着后端的数据处理、存储服务与前端的业务洞察。CSDN等大型互联网社区的实践表明,有效利用Hadoop生态进行数据处理,并选择合适的路径将处理结果服务于可视化,是释放大数据价值、提升产品智能与运营效率的必由之路。随着实时计算与交互式分析的进一步融合,Hadoop生态系统将继续在大数据可视化的底层支撑中扮演不可替代的角色。