Elasticsearch(简称ES)作为一种开源的分布式搜索和分析引擎,广泛应用于数据处理与存储服务中。其核心优势在于高效的全文检索、实时数据分析和大规模数据存储能力。以下将详细介绍ES的数据存储与查询基本原理,并探讨其在现代数据处理与存储服务中的关键作用。
一、ES数据存储基本原理
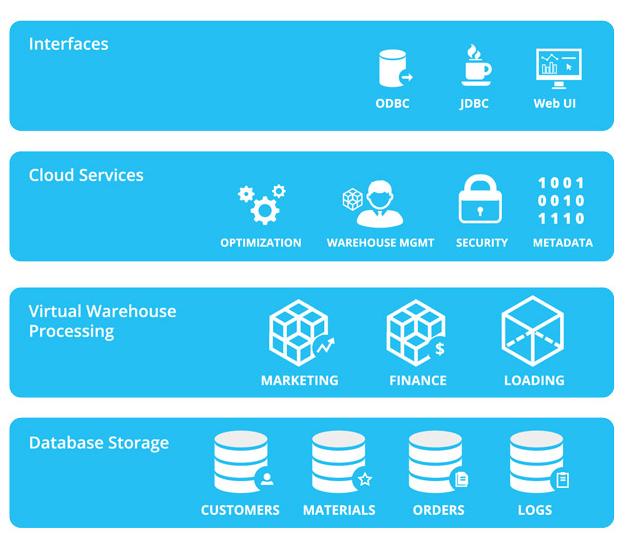
ES基于Apache Lucene构建,采用分布式架构存储数据,具有高可扩展性和容错性。其存储机制主要包括以下方面:
- 索引(Index)与文档(Document)结构:
- 索引是ES中数据的逻辑容器,类似于传统数据库中的表。每个索引包含多个文档,文档是基本的数据单元,以JSON格式存储。
- 文档通过唯一ID标识,并自动或手动分配到索引的分片中。
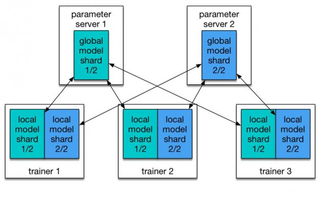
- 分片(Shard)与副本(Replica)机制:
- 索引被划分为多个分片,每个分片是一个独立的Lucene索引,分布在集群的不同节点上。这支持水平扩展,允许数据分布在多台机器上。
- 副本是分片的复制品,提供数据冗余和高可用性。当主分片故障时,副本可自动接管,确保服务不中断。
- 倒排索引(Inverted Index):
- ES使用倒排索引实现快速全文检索。倒排索引将文档中的词条映射到包含该词条的文档列表,类似于书籍的索引页。
- 在数据写入时,ES对文本进行分析(如分词、小写化),并构建倒排索引,从而在查询时快速定位相关文档。
- 数据写入与持久化流程:
- 当文档写入时,ES首先将其添加到内存缓冲区,然后定期刷新(refresh)到文件系统缓存,形成可搜索的段(segment)。
- 为了确保数据持久性,ES通过事务日志(translog)记录操作,并定期执行段合并(merge)和刷新到磁盘。
二、ES数据查询基本原理
ES的查询功能强大,支持多种查询类型,从简单匹配到复杂聚合分析。其查询流程如下:
- 查询解析与分发:
- 客户端发送查询请求到协调节点,协调节点解析查询(如使用Query DSL),并根据索引分片位置将请求分发到相关节点。
- 查询可以包括过滤、排序、分页和高亮等参数。
- 查询执行与评分:
- 每个分片独立执行查询,使用倒排索引快速匹配文档,并计算相关性评分(如TF-IDF或BM25算法)。
- 对于聚合查询,ES在分片级别执行初步聚合,然后在协调节点合并结果。
- 结果合并与返回:
- 协调节点收集各分片的查询结果,进行排序、评分合并和分页处理,最终返回给客户端。
- ES支持近实时(NRT)搜索,数据写入后通常在1秒内可被查询。
三、ES在数据处理与存储服务中的应用
在数据处理与存储服务中,ES扮演着关键角色,特别适用于日志分析、监控系统和搜索引擎等场景:
- 实时数据处理:ES能够处理流式数据,如应用日志或传感器数据,提供实时索引和查询能力。结合Kibana等工具,可实现数据可视化。
- 高可用性与扩展性:通过分片和副本机制,ES服务可以轻松扩展以处理PB级数据,同时保证高可用性,适合企业级存储需求。
- 复杂查询支持:ES支持全文检索、地理位置查询和聚合分析,使其在数据分析服务中优于传统数据库。例如,在电商平台中,可实现商品搜索和用户行为分析。
- 集成生态系统:ES常与Logstash和Beats等工具集成,形成ELK栈(Elastic Stack),提供端到端的数据采集、存储和查询解决方案。
Elasticsearch通过其高效的存储和查询机制,为现代数据处理与存储服务提供了强大支持。理解其基本原理有助于优化数据架构,提升系统性能和可靠性。在实际应用中,建议根据数据规模和查询需求合理配置索引、分片和副本,以实现最佳效果。