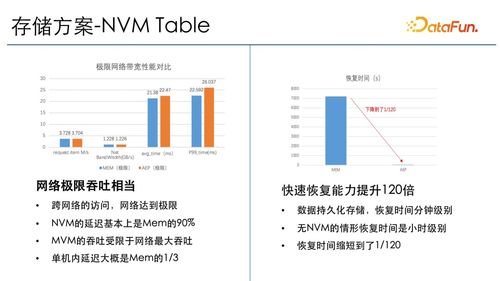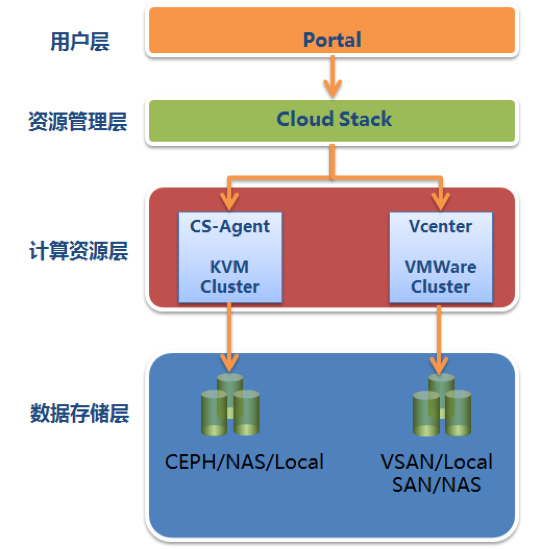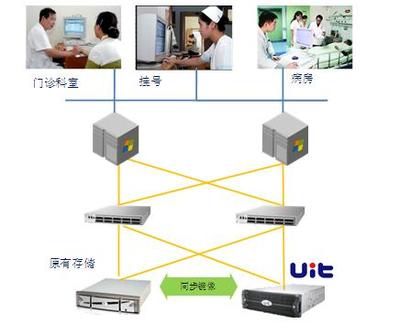
随着互联网用户规模迅速增长,亿级用户的数据存储与管理成为技术团队面临的核心挑战之一。王知无(知名技术博主)在CSDN博客中分享了他从Java开发转型至大数据领域的经验,特别强调数据处理与存储服务在构建高扩展性系统中的重要性。本文将探讨基于其思路的分布式数据存储解决方案,涵盖关键架构、技术选型及实践经验。
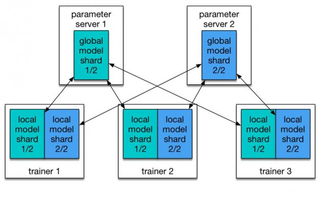
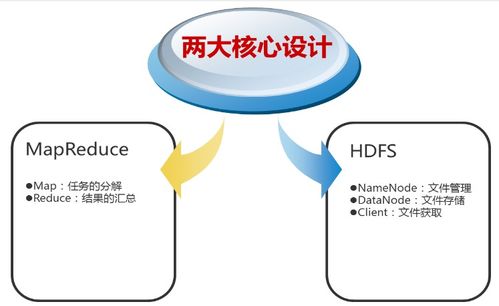
在亿级用户场景下,单机存储系统难以支撑海量数据的高并发读写和横向扩展需求。分布式数据存储通过将数据分散在多台服务器上,并结合负载均衡与容错机制,能够有效提升系统的可用性和性能。王知无指出,Java开发者转向大数据技术栈时,需掌握Hadoop、HBase、Cassandra等分布式存储框架,以及结合Kafka等消息队列进行实时数据处理。
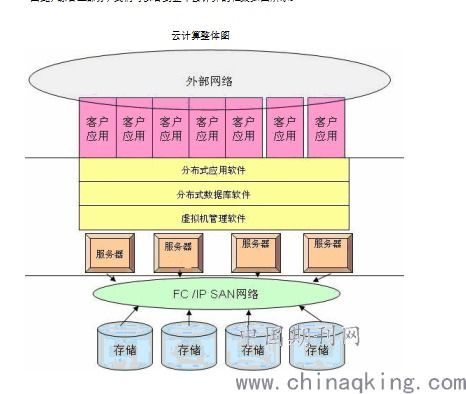
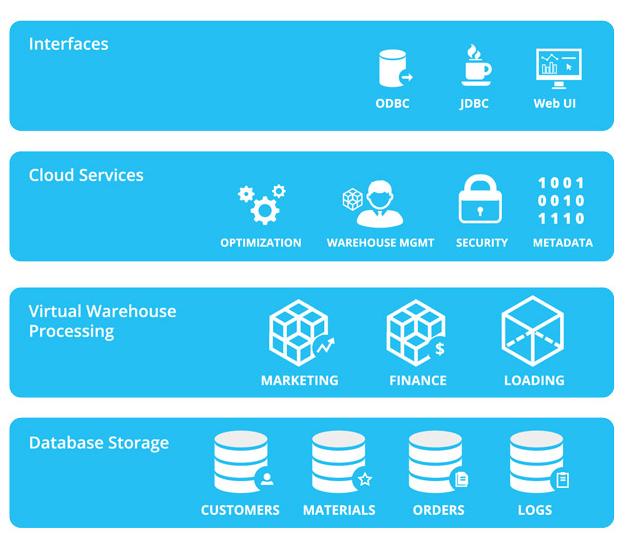
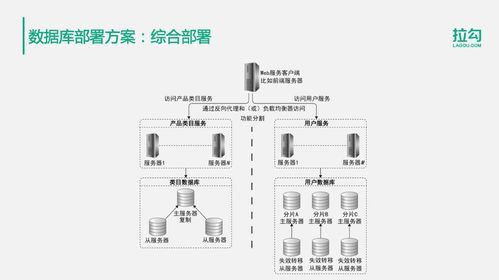
在数据处理与存储服务设计中,分层架构是关键。通常包括数据接入层、存储引擎层和查询服务层。数据接入层负责收集用户行为与业务数据,可采用Flume或Kafka实现高吞吐数据摄入;存储引擎层依据数据特性选择合适方案,如关系型数据用MySQL分库分表,非结构化数据用HDFS或对象存储;查询服务层则借助Elasticsearch或Presto提供快速检索与分析能力。
王知无强调,分布式存储必须考虑数据一致性与分区容错性,根据CAP理论权衡设计。例如,在电商或社交应用中,可采用最终一致性模型,结合副本机制和故障自动转移来保障服务不间断。监控与运维工具如Prometheus和ZooKeeper对于维护集群健康至关重要。
总结来看,亿级用户的数据存储解决方案需要综合技术深度与业务场景,从Java基础扩展到大数据生态,助力企业构建稳定、可扩展的数据基石。通过借鉴王知无的经验,开发者可以更高效地应对数据洪流,推动业务创新与增长。